
Co je to Kanban?
Protože tenhle článek je hlavně o implementaci Kanbanu, uvedu pouze krátkou definici pro neznalé. Odkazy pro další informace o Kanbanu najdete v článku Kanban z čistého nebe.Takže. Kanban je metoda pro limitování rozpracované práce (work-in-progress), která vychází z Lean developmentu a je definovaná pěti základními principy:
- Vizualizuj workflow.
- Limituj rozdělanou práci.
- Měr a spravuj flow.
- Udělej procesní politiky explicitní.
- Používej modely pro rozpoznání příležitosti ke zlepšení.
Obecně o projektu
Úkolem daného projektu bylo dodat sadu webových služeb (cca 60 business služeb). Daná technologie je z hlediska Kanbanu nepodstatná. Služby by měly splňovat základní SOA pradigmata - být autonomní, volně propojené (loose coupled), s velkou granularitou (coarse-grained). Implementované služby byly zasazeny do klasické middleware architektury, která vypadala velmi zhruba takto:
Vývoj služeb byl trekován v JIRA: co služba, to (GreenHopper) user story. Z hlediska projektu (Kanbanu) byly všechny dodávané služby unifikované - jejich dodávka se sestávala vždy ze stejných kroků, což Kanbanu (ale stejně tak třeba i Scrumu) vyhovuje. Jednotlivé kroky byly v JIRA vedeny jako technické subtasky dané user story.
- Kontrakt. Definice WSDL a příslušných XSD schemat.
- Mock. Jednoduchá implementace služby bez orchestrace, business logiky a volání backendů, tak aby frontendové komponenty měly vůči čemu vyvíjet.
- Implementace. Plná implementace služby včetně orchestrace, volání backendů, číselníkových překladů atd.
- Unit testy. Unit testy validací, orchestrace, business logiky, fault handlingu apod.
- Dokumentace. Jednak sebepopisná dokumentace kontraktu, jednak model orchestrace služby v CASE nástroji.
- Continuous Integration. Build, deployment, unit testing a undeployment v CI nástroji.
Něco málo o týmu
Na projektu jsme začínali dva. Pak to bez varování vyskočilo až na neúnosných 17 lidí, aby se to po nějakém čase ustálilo na rozumných 10 vývojářích.Tým byl tvořen z 90 % seniorními vývojáři, z nichž všichni se s Kanbanem setkávali poprvé. Lidé v týmu byli přátelsky a pozitivně naladěni a naštěstí se nenašel žádný kverulant, který by se metodiku snažil sestřelit.
Implementace 5 principů Kanbanu
Následujících pět sekcí je gró tohoto článku, aneb jak jsme se vypořádali s implementací jednotlivých principů Kanbanu.
1) Visualize Workflow

 |
| Elektronický JIRA Rapid Board |
JIRA má pro klasický Kanban Board vlastní název - Rapid Board. Vstupem do něj je běžný JIRA filtr, v obrázku výše jsou vyfiltrované pouze technické subtasky.
Obrazem elektronického workflow v JIRA byl fyzický Kanban Board, vytvořený z whiteboardu a lepicích lístečků. Každý člen týmu měl za úkol synchronizovat své úkoly v JIŘe s fyzickou tabulí.
 |
| Fyzický Kanban board |
Podobně jako v JIŘe byly vyfiltrovány pouze technické subtasky, tak i na fyzické tabuli byly jenom subtaskové lístečky. Subtasky z jedné user story se v sekci Done lepily na sebe a když byla user story kompletní, nahradily se lístečky lístkem jiné barvy, který reprezentoval danou user story.
2) Limit Work-in-Progress
 Limituj rozdělanou práci. Nastavení správného počtu úkolů, které mohou být v jednu chvíli rozpracovaný, je jedním z nejtěžších úkolů v Kanbanu. Hodně tady může napomoct teorie front a samozřejmě empirické zkoušení, testování a měření.
Limituj rozdělanou práci. Nastavení správného počtu úkolů, které mohou být v jednu chvíli rozpracovaný, je jedním z nejtěžších úkolů v Kanbanu. Hodně tady může napomoct teorie front a samozřejmě empirické zkoušení, testování a měření.V Kanbanu se někdy nastavuje pouze horní limit, já jsme nastavil horní i spodní a sice spodní limit byl počet vývojářů (velikost týmu mínus teamleader) a horní limit na dvojnásobek vývojářů. Každý vývojář tak musel mít přiřazený minimálně jeden úkol, ale maximálně mohl mít rozpracovaný pouze dva tasky.

3) Measure and Manage Flow
Měr a spravuj flow. Flow se v Kanbanu typicky zobrazuje pomocí diagramu Cumulative Flow, což dokáže i JIRA. Na obrázku níže představují barvy jednotlivé sekce ve flow: oranžová - To Do, modrošedá - In Progress, zelená - Done.Diagram má dva důležité rozměry. Horizontální délka dané sekce (nebo sekcí) říká, jak dlouho byl průměrně úkol v odpovídajícím stavu. Pokud vezmu například oranžovou a modrošedou barvu (= To Do + In Progress), říká mi tím diagram, jak (průměrně) dlouhý čas uběhl od zadání tasku do JIRy po jeho implementaci. Pokud bych vzal pouze úkoly ve stavu In Progress, dostávám velocitu tasku - jak dlouho trvala implementace úkolu.
Vertikální délka dané sekce říká, kolik bylo úkolů v dané sekci v určitý čas. V případě tasků v In Progress by to mělo odpovídat limitům WIP.
Ideálním stavem pro Kanban je, pokud je "tloušťka" tasků v In Progress (šedomodrá) více méně konstantní a rovnoměrně rostoucí. Alarmujícím příznakem je zvětšující se sekce To Do, což znamená, že se nám fronta začíná zahlcovat.
 |
| Diagram Cumulative Flow v JIRA |
Tolik teorie. V praxi tady vidím (u sebe) dluh, protože jsme nedokázali měřit velocitu týmu. JIRA sice umí vytvořit diagram kumulativního flow, ale neumožňuje s těmi daty nijak pracovat, tj. nejsem schopen spočítat, kolik tasků je tým schopný udělat např. za týden (velocita týmu) a jak průměrně dlouho trvá implementace úkolu. (Kdybych se mýlil a věděli byste, jak tyto údaje z JIRy dostat, dejte mi, prosím, vědět v komentářích.)
Inkriminované údaje by se daly například spočítat v Excelu, ale ten se mi nechtělo ručně vést, takže jsem na jejich zjištění rezignoval a pouze vizuálně kontroloval diagram, jestli nedochází k nějakým extrémním výkyvům.
Co se týká správy flow, průběžně jsem ho měnil podle zpětné vazby od týmu a také podle vlastní úvahy, jak jsem nad ním přemýšlel a pracoval s ním. Jako příklad můžu uvést nové stavy Blocked, In Test, nebo To Review.
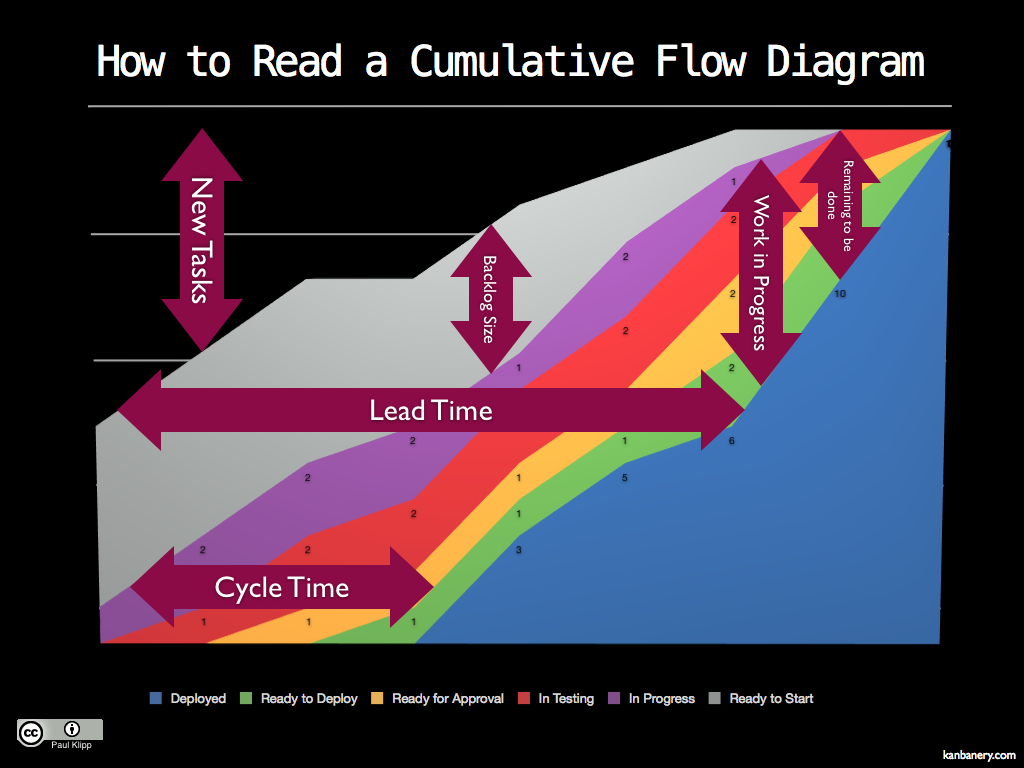
[update 13. 2. 2013] V komentáři jsem dostal odkaz na výborný obrázek, kde je Cumulative Flow diagram krásně vysvětlený:
 |
| Jak rozumět diagramu Cumulative Flow (zdroj Paul Klipp) |
4) Make Process Policies Explicit
Udělej procesní politiky explicitní. Procesní politiky jsme měli v podstatě pouze dvě, jednu z nich nepsanou. Ta definovala jak a kdo je zodpovědný za jednotlivé tasky v průběhu flow. Ačkoliv vznikl její model (viz další bod), nebyl do týmu v daném čase publikován.Kromě toho existoval na týmové wiki dokument s Definition of Done (DoD) pro jednotlivé technické subtasky. Tento dokument byl na wiki z toho důvodu, že jak už jsem psal výše, jednotlivé user story byly unifikované, takže nebylo potřeba uvádět DoD pro každý subtask do JIRy, ale dal se použít jeden centrální dokument vůči kterému šlo úkoly validovat.
5) Use Models to Recognize Improvement Opportunities
Používej modely pro rozpoznání příležitostí ke zlepšení. Tenhle ten princip jsem dosti dlouho ignoroval, protože jsem nevěděl jak ho uchopit a z počátku mi přišly daleko důležitější první tři principy Kanbanu. Nicméně, jeden model jsem nakonec vystřihnul. Jeden obrázek je za tisíc slov, takže jak fungovalo "samoobslužné" zpracování tasků:
 |
| Model flow |
Vývojáři si potom sami brali prioritní tasky a implementovali je. Hotové úkoly, ve stavu Done, pak reviewoval team leader.
Zlepšení flow, které mne díky tomuto jednoduchému modelu napadlo (ale už jsem neměl čas je zrealizovat) je přesunutí Review na roli vývojáře. Podobně, jako si vývojáři sami brali nové tasky, brali by si sami i tasky na review.
Jak se totiž v praxi ukázalo, Review bylo úzkým hrdlem flow. Jeden člověk (team leader) bude těžko zvládat dělat review a ještě držet agendu 10-15 lidí v týmu. Což je logické, byť to nemusí být na první pohled zřejmé.
Pravidelné týmové aktivity
Samotný Kanban neřeší další týmové náležitosti, ale pro lepší dokreslení řízení projektu je tady taky uvedu.Denní stand-up
Ráno jsme dělali klasický stand-up meeting. Nepoužívali jsme Scrumovské: "co jsem dělal včera a co budu dělat dneska?" Protože Kanban je zaměřený na flow a odstraňování jeho překážek, zněla otázka:Co budu dneska dělat a co mi v tom brání?
Týdenní code review
Jednou týdně, v pátek, probíhalo code review, kdy se procházely kontrakty, implementace služeb, unit testy, zkrátka věci definované v Definition of Done. Review probíhalo (s celým týmem) check-outem z verzovacího systému, procházení kódu v IDE a jeho promítání na stěnu, tak aby to viděl celý tým.Týdenní design review
Jednou týdně, ve středu, probíhalo design review, kdy se procházely návrhy orchestrací služeb, jejich implementací apod. Review probíhalo (s celým týmem) u whiteboardu, kde se ručně kreslilo zadání a diskutoval design.Shrnutí
Jak už jsem psal v úvodu, Kanban byl pro mne novinka a z počátku jsem k němu přistupoval opatrně. Přece jenom, pár zmršených implementací Scrumu už jsem viděl a Kanban je něco ještě daleko novějšího.Nicméně, snažil jsem se k tomu přistoupit zodpovědně a myslím, že se nám Kanban podařilo naimplementovat rozumně, korektně a funkčně.
Pokud bych to měl nějak celkově shrnout, myslím, že Kanban je životaschopný způsob, jak řídit vývojářský tým. Je vhodný nejenom pro supportní typy tasků (jak se obvykle traduje), ale i pro vývoj nových funkčností a systémů. Ve velmi dobré symbióze funguje Kanban s vývojem middlewarových služeb, protože požadavky na nové a úpravu stávajících služeb se jaksi přirozeně frontují.
Pokud bych tedy měl někdy v budoucnu volnou ruku ve výběru metodiky, o Kanbanu bych velmi vážně uvažoval.











{kind=link}